您现在的位置是:网站首页> 编程资料编程资料
Golang爬虫框架 colly的使用_Golang_
![]() 2023-05-26
532人已围观
2023-05-26
532人已围观
简介 Golang爬虫框架 colly的使用_Golang_
Golang爬虫框架 colly 简介
colly是一个采用Go语言编写的Web爬虫框架,旨在提供一个能够些任何爬虫/采集器/蜘蛛的简介模板,通过Colly。你可以轻松的从网站提取结构化数据,然后进行数据挖掘,处理或归档
项目特性
- 清晰明了的API
- 速度快(每个内核上的请求数大于1K)
- 管理每个域的请求延迟和最大并发数
- 自动cookie和会话处理
- 同步/异步/ 并行抓取
- 高速缓存
- 自动处理非Unicode编码
- 支持Robots.txt
- 支持Google App Engine
- 通过环境变量进行配置
- 可拓展
安装colly
go get -u github.com/gocolly/colly
第一个colly 应用
package main import ( "fmt" "github.com/gocolly/colly" ) func main() { c := colly.NewCollector() // goquery selector class c.OnHTML(".sidebar_link", func(e *colly.HTMLElement) { e.Request.Visit(e.Attr("href")) /* link := e.Attr("href") // Print link fmt.Printf("Link found: %q -> %s\n", e.Text, link) // Visit link found on page // Only those links are visited which are in AllowedDomains c.Visit(e.Request.AbsoluteURL(link))*/ }) c.OnRequest(func(r *colly.Request) { fmt.Println("url:",r.URL) }) c.Visit("https://gorm.io/zh_CN/docs/") } 回调函数的调用顺序
- OnRequest 在请求之前调用
- OnError 如果请求期间发生错误,则调用
- OnResponseHeaders 在收到响应标头后调用
- OnResponse 收到回复后调用
- OnHTML OnResponse如果接收到的内容是HTML ,则在此之后立即调用
- OnXML OnHTML如果接收到的内容是HTML或XML ,则在之后调用
- OnScraped 在OnXML回调之后调用
实例
func collback() { // 添加回调 收集器 c:= colly.NewCollector() c.OnRequest(func(r *colly.Request) { fmt.Println("请求前调用:OnRequest") // fmt.Println("Visiting", r.URL) }) c.OnError(func(_ *colly.Response, err error) { fmt.Println("发生错误调用:OnReOnError") //log.Println("Something went wrong:", err) }) /* c.OnResponseHeaders(func(r *colly.Response) { //高版本已经不用了 fmt.Println("Visited", r.Request.URL) }) */ c.OnResponse(func(r *colly.Response) { fmt.Println("获得响应后调用:OnResponse") //fmt.Println("Visited", r.Request.URL) }) c.OnHTML("a[href]", func(e *colly.HTMLElement) { fmt.Println("OnResponse收到html内容后调用:OnHTML") //e.Request.Visit(e.Attr("href")) }) /* c.OnHTML("tr td:nth-of-type(1)", func(e *colly.HTMLElement) { fmt.Println("First column of a table row:", e.Text) })*/ c.OnXML("//h1", func(e *colly.XMLElement) { fmt.Println("OnResponse收到xml内容后调用:OnXML") //fmt.Println(e.Text) }) c.OnScraped(func(r *colly.Response) { fmt.Println("结束", r.Request.URL) }) c.Visit("https://gorm.io/zh_CN/docs/") } 得到的:
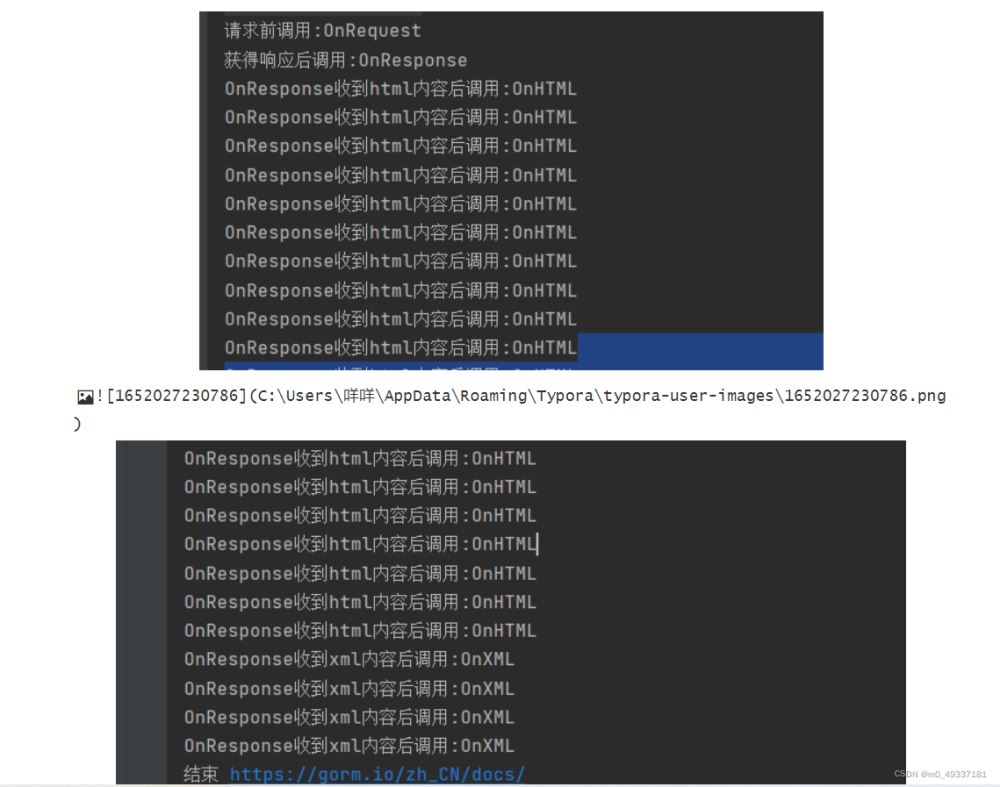
colly 的配置
设置UserAgent
//设置UserAgent的两种方式: /* //方式一 : c2 := colly.NewCollector() c2.UserAgent = "xy" c2.AllowURLRevisit = true*/ /* //方式二 : c2 := colly.NewCollector( colly.UserAgent("xy"), colly.AllowURLRevisit(), )*/ 设置Cookie
//设置cookie的两种方式 //方式一:通过手动网页添加cookies c.OnRequest(func(r *colly.Request) { r.Headers.Add("cookie","_ga=GA1.2.1611472128.1650815524; _gid=GA1.2.2080811677.1652022429; __atuvc=2|17,0|18,5|19") }) // 方式二 :通过url 添加cookies siteCookie := c.Cookies("url") c.SetCookies("",siteCookie) HTTP配置
Colly使用Golang的默认http客户端作为网络层。可以通过更改默认的HTTP roundtripper来调整HTTP选项。
c := colly.NewCollector() c.WithTransport(&http.Transport{ Proxy: http.ProxyFromEnvironment, DialContext: (&net.Dialer{ Timeout: 30 * time.Second, KeepAlive: 30 * time.Second, DualStack: true, }).DialContext, MaxIdleConns: 100, IdleConnTimeout: 90 * time.Second, TLSHandshakeTimeout: 10 * time.Second, ExpectContinueTimeout: 1 * time.Second, } colly页面爬取和解析
页面爬取和解析重点方法是 onHTML 回调方法
c.OnHTML("a[href]", func(e *colly.HTMLElement) { fmt.Printf("e.Name:%v\n",e.Name) e.Request.Visit(e.Attr("href")) }) func html() { c:= colly.NewCollector() c.OnHTML("#sidebar", func(e *colly.HTMLElement) { //fmt.Printf("e.Name:%v\n",e.Name) //名字 //fmt.Printf("e.Text:%v\n",e.Text) //文本 ret, _ := e.DOM.Html() // selector 选择器 fmt.Printf("ret:%v\n",ret) }) c.OnRequest(func(r *colly.Request) { fmt.Println("url:",r.URL) }) c.Visit("https://gorm.io/zh_CN/docs/") } 第一个参数是:goquery选择器,可以元素名称,ID或者Class选择器,第二个参数是根据第一个选择器获得的HTML元素结构如下:
colly框架重构爬虫
package main import ( "fmt" "github.com/gocolly/colly" ) func main() { c:= colly.NewCollector() c.OnHTML(".sidebar_link", func(e *colly.HTMLElement) { // 左侧链接 href := e.Attr("href") if href != "index.html"{ c.Visit(e.Request.AbsoluteURL(href)) } }) c.OnHTML(".article-title", func(h *colly.HTMLElement) { // 选择链接之后的标题 title := h.Text fmt.Printf("title: %v\n",title) }) c.OnHTML(".article", func(h *colly.HTMLElement) { //内容 content, _ := h.DOM.Html() fmt.Printf("content: %v\n",content) }) c.OnRequest(func(r *colly.Request) { fmt.Println("url:",r.URL.String()) }) c.Visit("https://gorm.io/zh_CN/docs/") } 到此这篇关于Golang爬虫框架 colly的使用的文章就介绍到这了,更多相关Golang colly内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
您可能感兴趣的文章:





